En primer lugar cargamos las librerías que necesitamos. Utilizamos la librería tydiverse que engloba muchas de las que vamos a necesitar posteriormente (dplyr, lubridate, plotly…)
Análisis del conjunto de datos
Cargamos los datos desde el csv en el dataframe llamado ‘reviews’.
Vamos a extraer algo de información. En primer lugar, un resumen de los datos:
Además del resumen que la función summary nos ofrece, detectamos algunas cosas:
Además vemos que tenemos la información de los hoteles con sus direcciones y coordenadas. Intentaremos extraer el país en el que se encuentra cada hotel. De esta forma podremos extraer información del origen y destino de los turistas.
Preparación de los datos
Vamos a resolver algunas preguntas iniciales.
¿Cuántos hoteles tenemos? Calculamos el número unico de hoteles y de direcciones. Así nos aseguramos de que no tengamos dos hoteles que se llamen igual en diferentes ubicaciones.
Tenemos 1492 y 1493 direcciones por lo que, efectivamente, tenemos 2 hoteles que se llaman igual pero se encuentran en dos ubicaciones diferentes. Es algo que tendremos que tener en cuenta durante todo el análisis posterior que hagamos.
Y ahora veamos las nacionalidades de los clientes.
Tenemos 227 nacionalidades diferentes.
Vamos a preparar algunos datos que necesitamos. En primer lugar vamos a asignar el formato de fecha a la variable que contiene la fecha en la que se realizó la review. Para ello vamos a utilizar el paquete lubridate
También vamos a asegurarnos de que nuestros campos de texto no tengan fallos. Para ello vamos a eliminar los espacios del principio y final con la función str_trim. Lo aplicamos a las variables del nombre del hotel, de la dirección y de los comentarios positivos y negativos de los clientes.
Vamos ahora a convertir el campo days_since_review a numérico eliminando la coletilla ‘days’ y revisamos cuántos valores distintos tenemos.
Observamos que en algunos campos se utilizaba el término ‘day’ y en otros el término ‘days’. Vamos a eliminar también en los que incluyen ‘day’.
Y ya podemos convertir este campo a numérico:
Vamos a revisar que no haya errores en los campos de comentarios positivos y negativos. Para ello seleccionamos las filas que tienen 0 en el recuento de palabras de comentario positivo y vemos qué valores contienen.
Vemos que el único valor que contienen en ‘No positive’ por lo que está todo correcto. Hacemos lo mismo con los comentarios negativos:
Y vemos que sólo contienen el valor ‘No Negative’. Deducimos, por tanto, que el recuento de palabras se ha hecho previo a la limpieza de datos y los campos vacíos se han sustituido por ‘No positive’ y ‘No negative’.
Obtener el país del hotel
Queremos obtener el país de cada hotel. Para ello vamos a utilizar las coordenadas pero nos faltan las de algunos hoteles. Para no perder estos datos, vamos a completar los datos del dataset.
En primer lugar revisamos los valores NA que tenemos en los campos de latitud y longitud.
Vemos que tenemos 3268 valores en los que falta la latitud y la longitud. Aunque podríamos descartarlos no queremos perder información. Los aislamos para trabajar con ellos:
Como tenemos demasiados registros, vamos a ver de los hoteles que no tenemos las coordenadas:
Tenemos los 17 hoteles mostrados. Vamos a obtener las coordenadas de sus direcciones. Para ello vamos a utilizar el servicio de geocoding de Google con el paquete ggmap (para esto tenemos que configurar nuestra API Key del servicio de Google, lo cual hemos hecho previamente en R siguiendo las instrucciones del paquete ggmap).
Ya tenemos las coordenadas de los hoteles que nos faltaban. Vamos a asignarlas al dataframe original. Primero nos quedamos sólo con las columnas que nos interesan para hacer un inner join. Nos quedamos con la dirección del hotel (recordamos que era fundamental utilizar la dirección y no el nombre para evitar errores) y la latitud y longitud. También eliminamos las columnas de longitud y latitud de nuestro dataframe con todos los NA para asignarle las nuevas calculadas.
Finalmente hacemos la unión de las direcciones con sus latitudes y longitudes.
Ahora eliminamos las filas con las latitudes y longitudes NA en nuestro dataset principal y añadimos estas mismas filas ya con los datos completos:
Ya tenemos las coordenadas de todos nuestros hoteles.
Ahora, utilizando la librería rworldmap y la función coords2country que creamos, vamos a convertir esas coordenadas en países.
Ya lo tenemos. Vamos a ver de cuántos países tenemos información:
Vemos que tenemos hoteles de 6 países, en concreto Holanda, Reino Unido, Francia, España, Italia y Austria.
Comprobamos que no tengamos campos vacíos:
Y revisamos que no tengamos valores NA en ningún otro campo:
No tenemos ningún NA en nuestros datos. Ahora vamos a revisar el campo Tags que es un poco más compleja porque agrupa mucha información.
Lo primero que observamos es que incluye 4 o 5 variables que podemos clasificar como: Tipo de viaje, si viaja solo o acompañado (en grupo, en familia), tipo de habitación, las noches que se ha alojado en el hotel y si la reserva se ha realizado desde un dispositivo móvil. También observamos que no todas las filas tienen todos los tags, lo cual nos complica un poco la tarea de limpieza de datos. Por otro lado, vemos que tiene 55242 combinaciones diferentes de etiquetas, aunque la mayoría de etiquetas se repiten, siendo todas ellas combinaciones de diferentes opciones.
Vamos a ver cuántas etiquetas posibles tenemos
Tenemos casi 2500 etiquetas.
Sabemos que una de las opciones es que los clientes viajen con mascota (With a pet). Vamos a incluir este dato como una columna adicional:
Observamos que hay 1405 clientes que viajaron con mascota. Hagamos lo mismo para ver cuántos clientes publicaron su review desde el móvil o tablet:
Aquí vemos que hay más de 300.000 usuarios que hicieron la reseña desde un dispositivo móvil por los 200.000 que no lo hicieron de esta forma.
Otro de los datos que hemos visto que incluían las etiquetas era el número de noches. Vamos a extraer este dato de los clientes que lo tengamos.
Tenemos algunos datos desconocidos y otros que varían entre 1 y 31 noches.
Vamos a crear una función que nos permitirá comprobar si en el campo tags tenemos alguna de las líneas que nos indica cuántas noches se alojó el cliente y lo añadimos a una nueva columna de nuestro dataframe llamada nights:
Observamos que sólo tenemos 192 valores desconocidos, lo cual está muy bien. 190.000 turistas se alojaron una noche, 134.000 lo hicieron dos noches y 95.000 pernoctaron 3 noches. A partir de aquí la cifra desciende progresivamente.
Ahora vamos a eliminar los tags que ya hemos utilizado de nuestra lista y seguimos explorando:
También hemos visto que los comentarios podían venir de clientes que hiciesen el viaje por ocio (Leisure trip) o por trabajo (Business trip). Vamos a revisar que sólo tengamos esas dos opciones y creamos el campo ‘trip’ en nuestro dataframe con este valor:
Vemos que la mayoría de nuestros clientes (más de 400.000) viaja por ocio, unos 80.000 viajan por trabajo y de unos 15.000 desconocemos este dato.
Vemos que muchos de los otros tags que encontramos hacen referencia al tipo de habitación. En este caso no lo vamos a utilizar ya que vemos que hay miles de valores posibles, lo cual no es útil para nuestro análisis y el posterior modelo, y además es un valor que no es útil para analizar entre diferentes hoteles ya que pueden utilizar diferentes nombres para idénticos servicios.
Así pues, eliminamos las referencias que no nos interesan. Para ello vamos a descartar los tags que contengan palabras que habitualmente podemos asociar al tipo de habitación:
Ya tenemos un grupo muy reducido de 24 tags entre los que nos encontramos con algunos muy específicos de algún hotel que no habíamos tenido en cuenta y otros que nos sugieren que también tenemos las reviews etiquetadas según si el viaje se ha hecho en pareja, en familia… Vamos a seleccionar estas etiquetas y añadirlas a nuestro dataframe:
En este caso vemos que no tenemos ningún valor ‘Other’ lo cual significa que hemos extraído este tag para todos nuestros registros. 250.000 clientes viajaron en pareja y 100.000 lo hicieron solos, el resto se reparten entre familias, grupos y viajes con amigos.
Antes de acabar vamos a eliminar la columna Tags de nuestros datos, ya que la hemos desgranado en los campos que nos interesaban y no necesitamos mantenerla como tal.
Análisis exploratorio
Ya tenemos nuestros datos preparados, ahora vamos a ver qué información podemos extraer de ellos.
Vamos a trabajar un modelo de machine learning que nos ayude a predecir la puntuación de los clientes sobre un hotel así que vamos a analizar la variable de la puntuación de los hoteles y las puntuaciones de los clientes.
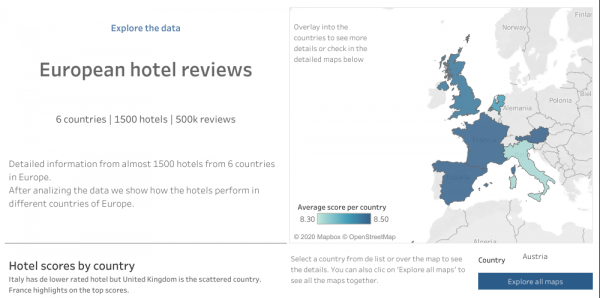
Veamos qué puntuación tenemos de los hoteles de cada país.

Vemos que la puntuación media está sobre 8.5 excepto Italia (veíamos al inicio que la media de este campo era de 8.4), que es un poco inferior. El hotel con la puntuación más alta está en Francia y la más baja en Italia. Descubrimos también que ningún hotel tiene una puntuación inferior a 5. El Reino Unido es el que tiene la mayor dispersión en las puntuaciones con bastantes hoteles con puntuaciones inferiores.
Vamos a ver cómo se reparten las valoraciones de los clientes.

Vemos que la puntuación que más dan los clientes de de 10 y que la tendencia es clara hacia las puntuaciones altas. Vemos también que, en general, las puntuaciones fluctúan evitando los números redondos y que tienden hacia valores intermedios con decimales. Esto se puede deber a cómo se calculan las puntuaciones, ya que a veces es la media de varias puntuaciones a aspectos específicos. Curiosamente, esta norma se ‘rompe’ en el caso del 5, donde vemos que si que hay un repunte de puntuaciones.
Veamos los resultados con un histograma.

Obviamente el resultado es parecido. Destacan las valoraciones que dan 10 puntos y el número de valoraciones desciende a medida que lo hacen las puntuaciones.
Con estos gráficos también verificamos que no hay ningún dato incorrecto ya que ninguna puntuación se sale de los valores que podíamos esperar (no hay valores negativos ni mayores de 10).
Para profundizar un poco en el análisis podemos sacar estos datos desglosados por país de destino:

No detectamos que haya grandes variaciones entre la distribución de las puntuaciones entre los distintos países. En todos los casos vemos que aumentan las puntuaciones a partir del 7.
Vamos a ver cuántas reviews incluyen comentarios positivos por país. Calculamos también la media y la representamos en el gráfico para tener ese valor como referencia.

Vemos que el 93% de las reviews incluyen comentarios positivos sobre el hotel o la estancia. España es el país que destaca ligeramente, Italia se queda en la media y Reino Unido es el único país que baja la media.
¿Y cobre los comentarios negativos? Hacemos lo mismo que con los positivos.
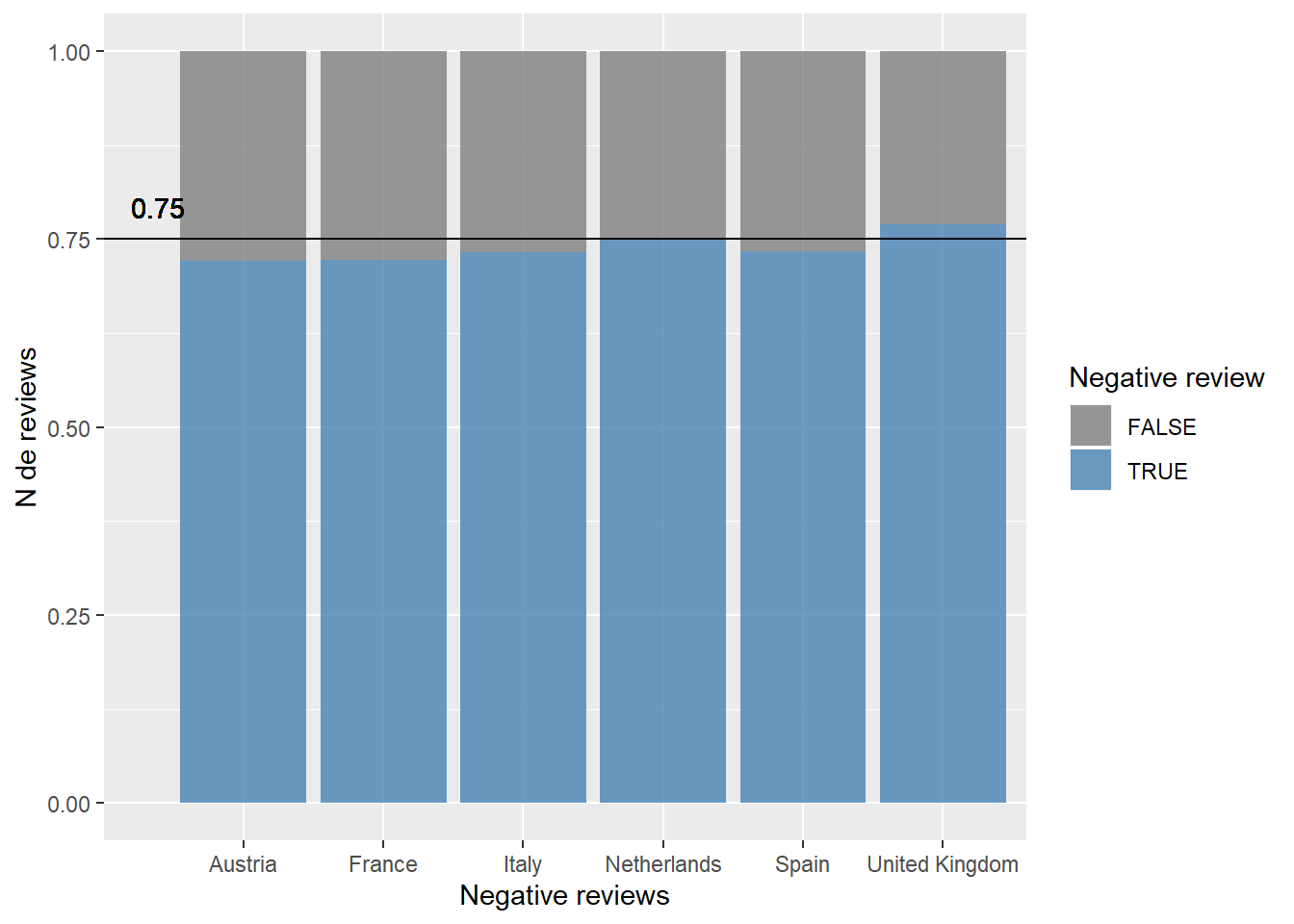
La media baja hasta el 75% de los clientes que deja comentarios negativos sobre su estancia. Reino Unido es el único destino que supera este umbral, seguido de Italia que está justo en la media.
Vemos que Reino Unido también es el país del que tenemos más reviews, lo cual puede afectar a los resultados antes vistos ya que tiene más peso en los cálculos.

De hecho, vemos que 400 de los 1493 hoteles que tenemos son de United Kingdom.
Vamos a ver de qué países a qué destinos viajan los turistas. Cargamos el paquete networkD3 que utilizaremos después, creamos un nuevo dataframe con los valores que necesitamos y creamos el diagrama con la librería plotly. Convertimos los países a texto y creamos un vector con todos los países que tenemos en nuestros datos:

Debido a la gran variedad de países de origen no podemos ver demasiado a simple vista pero sí que podemos extraer alguna conclusión. Por ejemplo, a pesar de que United Kingdom tiene la mayoría de los hoteles, tiene turistas de 199 países por los 180 de Holanda y España o los 200 de Francia. Asimismo 170.000 de los 245.000 turistas de UK viajan dentro del país.
Para obtener algo más de información, vamos a hacer el mismo cálculo pero por continente en vez de por país. Lo hacemos con la librería networkD3 que hemos cargado antes.
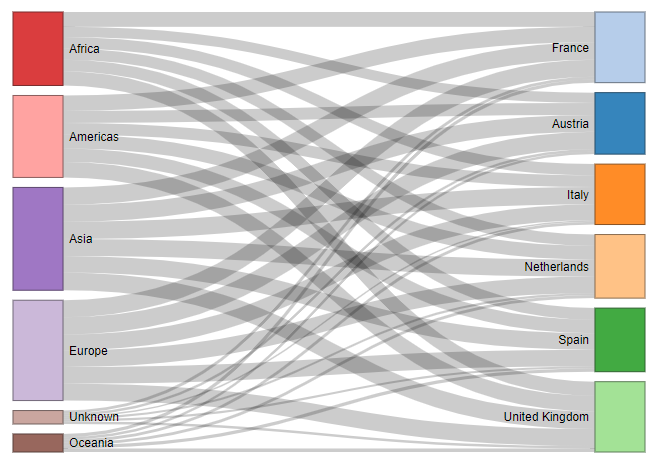
En este caso los datos están muy repartidos pero podemos igualmente sacar algunas conclusiones: Desde África y América se viaja más a Francia y Reino Unido que al resto de países. El resto de casos no cuenta con grandes diferencias.
Antes hemos sacado las variables de tipo de viaje y motivo del viaje. Vamos a ver cómo se correlacionan:
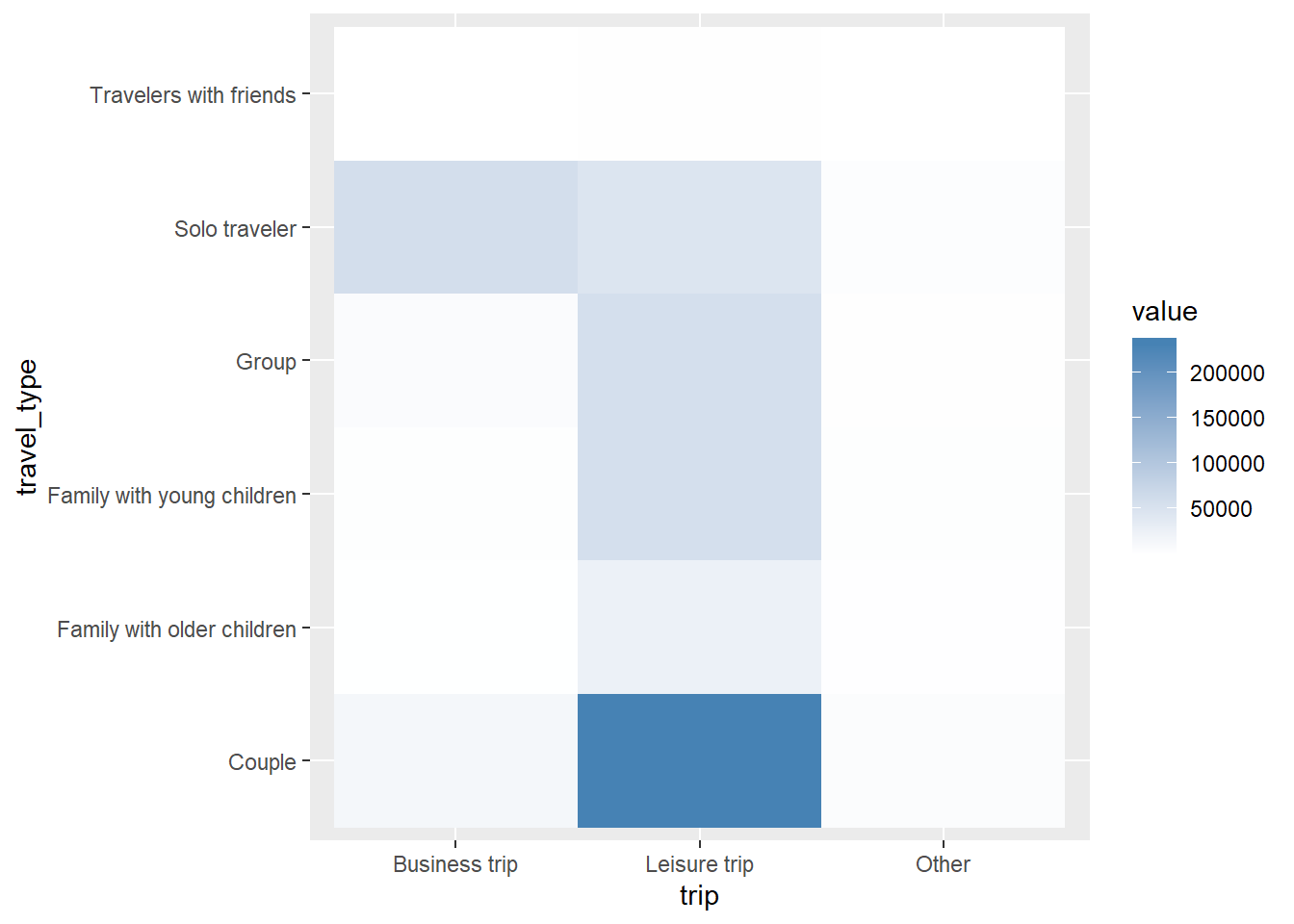
Este sencillo histograma nos muestra algo que a priori parece obvio y es que las personas que viajan por trabajo suelen hacerlo en solitario, mientras que las pareja, los grupos y las familias suelen hacerlo por placer.
Vamos a analizar brevemente los comentarios que escriben los clientes sobre los hoteles. Tenemos los campos del recuento de palabras de los comentarios positivos y negativos. Vamos a enfrentarlos con las puntuaciones de los clientes:

En el caso de los comentarios positivos vemos que hay una tendencia a que sean más largos cuando las puntuaciones son buenas. En el caso de los comentarios negativos vemos que hay mucha mayor densidad de comentarios largos y aumenta en las puntuaciones bajas y se concentra por debajo de las 200 palabras en las puntuaciones altas.
Por lo tanto, podemos considerar que estos dos campos pueden ser buenos indicadores de la puntuación del cliente, puesto que existe una tendencia, aunque no determinante dado su gran dispersión.
Con el campo de ‘Positive review’ y ‘Negative review’ que hemos sacado antes, vamos a ver si estos afectan a la puntuación.

Efectivamente, las reviews que incluyen comentarios positivos tienden a puntuar más alto, mientras que las valoraciones con comentarios negativos puntúan más bajo. De hecho, vemos que la mayoría de reviews sin comentarios negativos se concentra en puntuaciones muy altas. Otros buen indicador para nuestro modelo.
Ahora veamos lo mismo pero con el campo de si el comentario se ha realizado desde el móvil o no.

En este caso vemos que no hay ninguna relación entre la puntuación y si el comentario se realizó desde el móvil o no. Por lo tanto, podemos descartar esta variable de nuestro modelo.
Veamos qué pasa según el motivo del viaje:

En este caso vemos pequeñas variaciones. Las puntuaciones en los viajes de placer suele ser superior a la de los viajes de trabajo.
¿Y por tipo de viaje? Lo vemos en este gráfico.

Aquí sí que vemos claramente que en los viajes con amigos la puntuación suele ser más alta mientras que los que viajan solos suelen ser los que más bajo puntúan. Las estancias de viajes en pareja también suelen recibir buenas puntuaciones.
También tenemos el dato de valoraciones que tiene el hotel. Vamos a ver si afecta a la puntuación:

En este caso, nuevamente, vemos que no hay ninguna relación por lo que podemos descartar esta variable de nuestro modelo posterior.
¿Qué pasa cuando los clientes se alojan más días? Vamos a ver la puntuación según las noches que se alojaron los clientes.

Como es lógico, en las estancias cortas las puntuaciones se reparten mucho pero sí que observamos que, a medida que el número de noches aumenta, las puntuaciones también lo hacen.
¿Y la fecha tiene algo que ver con la puntuación?

Vemos que los registros se distribuyen linealmente en el tiempo y que no parece haber ninguna relación entre la fecha y la puntuación que los clientes dan al hotel. Podemos descartar, por lo tanto, tanto esta variable como la que indica los días desde la review que es un cálculo derivado de ésta.
Otro dato que tenemos el el número de reviews que ha publicado un usuario. Nuevamente vemos si tiene relación con la puntuación otorgada:

Nuevamente observamos cierta tendencia a que, a mayor número de reviews, más valoraciones positivas.
Creación del modelo
Terminado el análisis, vamos a preparar nuestro modelo de aprendizaje para prever las valoraciones de los clientes. Antes de empezar vamos a limpiar nuestro espacio de trabajo para liberar recursos:
Vamos a crear el modelo. Primero preparamos los datos seleccionando las variables que vamos a utilizar y eliminando las que hemos descartado.
Predicciones con el paquete Caret
En este caso vamos a utilizar el paquete caret y sus opciones para hacer nuestro modelo con el algoritmo MARS Cargamos el paquete Caret y hacemos nuestras particiones de test y entrenamiento.
Dado que tenemos un conjunto de datos muy grande, y tras hacer varias pruebas, hemos detectado que con el 40% de los registros para entrenamiento obtenemos un buen resultado, y el mismo no mejora incluyendo más datos en nuestro conjunto de entrenamiento.
Revisamos que se mantengan las proporciones.
Observamos que las proporciones se mantienen en la mayoría de casos.
Vamos a revisar las variables con varianza cercana a cero
Eliminamos estas variables dado que podrían desvirtuar nuestro modelo:
Tenemos la variable ‘pet’ que tiene una varianza cercana a cero por lo que la eliminamos de nuestro modelo
En este caso no tenemos ninguna variable altamente correlada por lo que mantenemos todas en nuestro modelo.
Ahora preparamos los datos con la función preprocess para poder aplicar el modelo.
Aplicamos el modelo de regresión MARS con el método ‘earth’. Nuevamente, y tras diversas pruebas, detectamos que con los parámetros abajo indicados obtenemos un rendimiento aceptable y aumentando el numero de repeticiones no mejoramos el resultado.
Así que procedemos a ejecutar nuestro modelo con los parámetros que hemos detectado como óptimos.
Caret nos indica el mejor modelo en función de las simulaciones calculadas. En este caso obtenemos un modelo que es capaz de predecir las puntuaciones de los clientes con una variación de un punto. Vemos también que el valor MAE de nuestro modelo final es menor, lo cual nos indica que predice bastante bien la mayoría de puntuaciones aunque en algunas puntuales la desviación sea mayor.
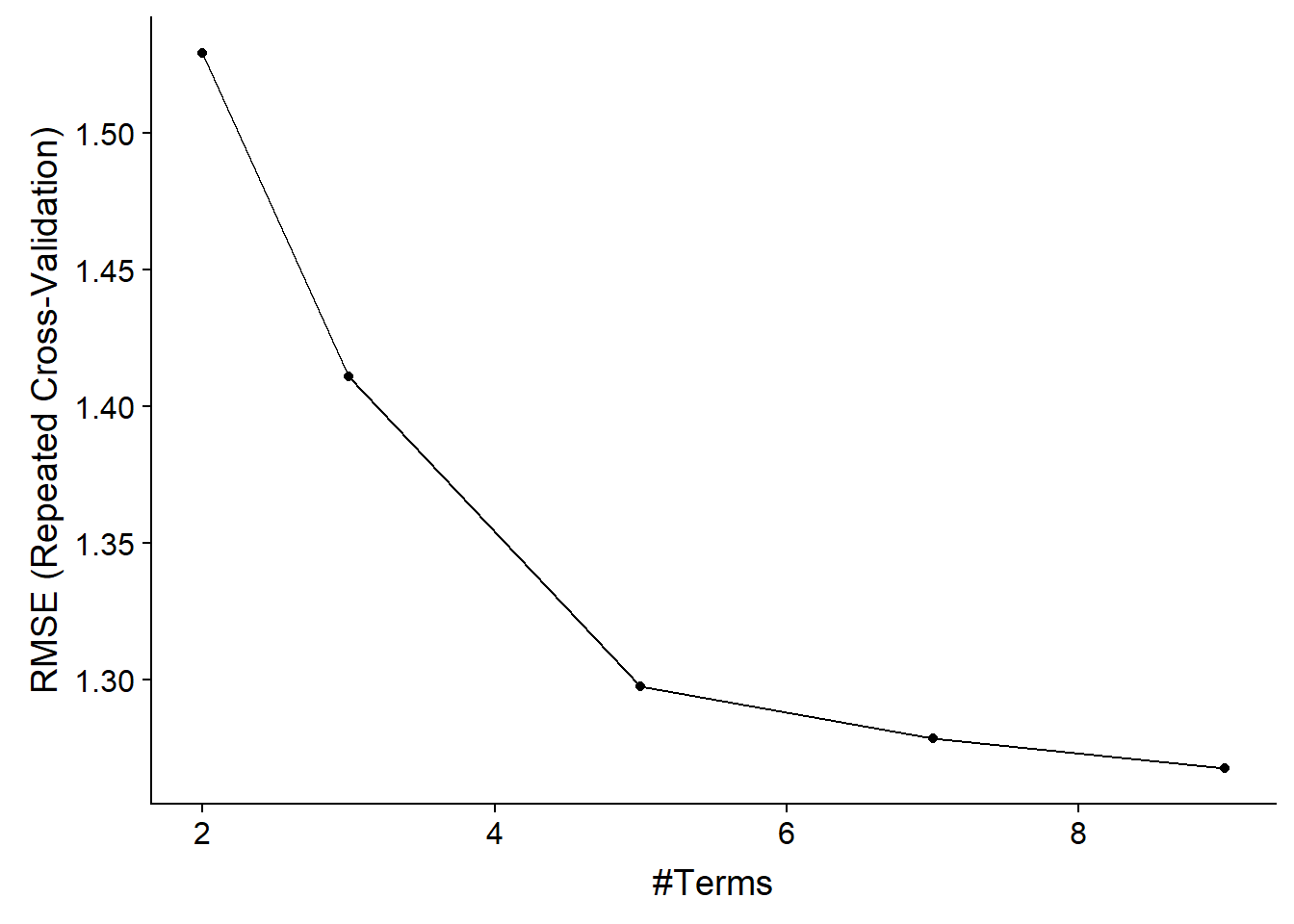
Vemos el resumen del modelo.
Revisamos cuál es el mejor modelo con el campo bestTune.
Y lo vemos un una gráfica.
Observamos también la importancia de cada variable en nuestro modelo.

Así pues, ya podemos crear las predicciones de nuestro modelo de test
Y observamos cómo se comporta respecto a las observaciones.
Vemos que, aunque en algunos casos tenemos cierta desviación, los datos obtenidos con nuestro modelo se aproximan bastante a las observaciones reales.
Finalmente podemos calcular los valores RMSE, R2 y MAE de nuestro modelo para ver si el resultado obtenido es bueno.
Observamos que los valores son casi idénticos a los de nuestro modelo por lo que podemos concluir que nuestro modelo es fiable.